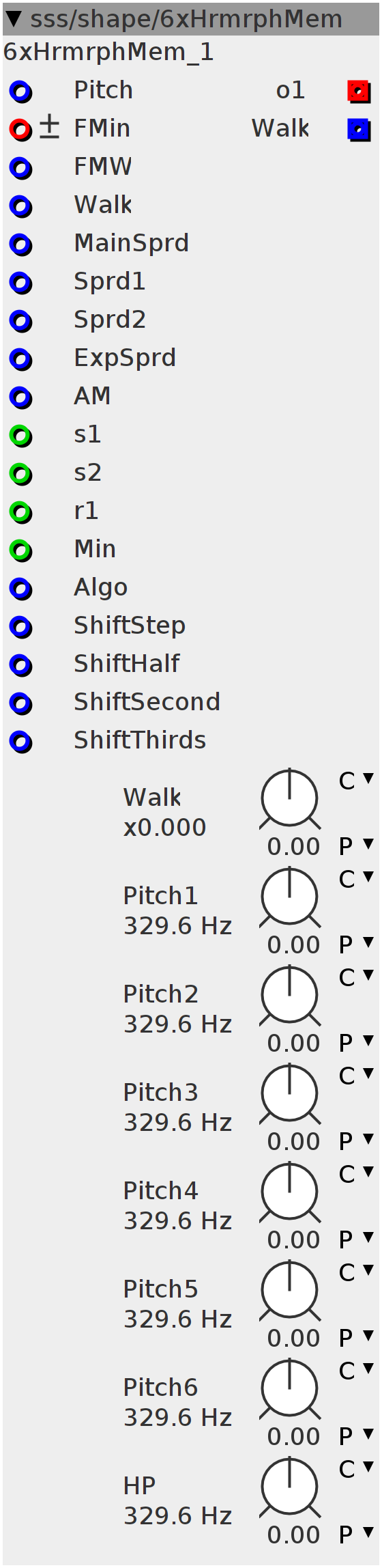
6xHrmrphMem
input multiplexer. Output is i1 when s < 1, i[i] when....
Inlets
int32 harmonic morph Stepsize 1
int32 harmonic morph Stepsize 2
int32 harmonic max Range 1
int32 harmonic minimum (1)
frac32 Pitch
frac32 FMW
frac32 Harmonic position 1
frac32 Harmonic position 2
frac32 Harmonic position 3
frac32 Harmonic position 4
frac32 Harmonic position 5
frac32 Harmonic position 6
frac32 Algo
frac32 ShiftStep
frac32 ShiftHalf
frac32 ShiftSecond
frac32 ShiftThirds
frac32buffer.bipolar FMin
Outlets
frac32buffer o1
frac32 Walk
Parameters
frac32.s.map.ratio Walk
frac32.s.map.pitch Pitch1
frac32.s.map.pitch Pitch2
frac32.s.map.pitch Pitch3
frac32.s.map.pitch Pitch4
frac32.s.map.pitch Pitch5
frac32.s.map.pitch Pitch6
frac32.s.map.pitch HP
int32_t a1;
int32_t b1;
int32_t c1;
int32_t d1;
int32_t r11;
int32_t r21;
int32_t s11;
int32_t s21;
int32_t a2;
int32_t b2;
int32_t c2;
int32_t d2;
int32_t r12;
int32_t r22;
int32_t s12;
int32_t s22;
int32_t a3;
int32_t b3;
int32_t c3;
int32_t d3;
int32_t r13;
int32_t r23;
int32_t s13;
int32_t s23;
int32_t a4;
int32_t b4;
int32_t c4;
int32_t d4;
int32_t r14;
int32_t r24;
int32_t s14;
int32_t s24;
int32_t a5;
int32_t b5;
int32_t c5;
int32_t d5;
int32_t r15;
int32_t r25;
int32_t s15;
int32_t s25;
int32_t a6;
int32_t b6;
int32_t c6;
int32_t d6;
int32_t r16;
int32_t r26;
int32_t s16;
int32_t s26;
int32_t x1;
int32_t x2;
int32_t x3;
int32_t x4;
int32_t x5;
int32_t x6;
uint32_t phase;
uint32_t trace;
// oscillators
uint32_t Phase1a;
uint32_t Phase2a;
uint32_t Phase3a;
uint32_t Phase4a;
uint32_t Phase5a;
uint32_t Phase6a;
uint32_t Phase1b;
uint32_t Phase2b;
uint32_t Phase3b;
uint32_t Phase4b;
uint32_t Phase5b;
uint32_t Phase6b;
// FM
int32_t FM;
int32_t SO1;
int32_t SO2;
int32_t SO3;
int32_t SO4;
int32_t SO5;
int32_t SO6;
int32_t TO;
uint32_t freq1;
uint32_t freq2;
uint32_t freq3;
uint32_t freq4;
uint32_t freq5;
uint32_t freq6;
int32_t AlgoX;
int32_t algoM;
int32_t algo2;
int32_t algo3;
int32_t algo4;
int32_t algo5;
int32_t algo6;
int32_t r;
int32_t frq;
int32_t val1;
int32_t val2;
int32_t val3;
int32_t val4;
int32_t val5;
int32_t val6;
int32_t val7;
int32_t aG;
int32_t bG;
int32_t cG;
int32_t dG;trace = 0;
Phase1a = 0;
Phase2a = 0;
Phase3a = 0;
Phase4a = 0;
Phase5a = 0;
Phase6a = 0;int k11;
int k21;
int k12;
int k22;
int k13;
int k23;
int k14;
int k24;
int k15;
int k25;
int k16;
int k26;
int32_t sa1;
int32_t sb1;
int32_t sa2;
int32_t sb2;
int32_t sa3;
int32_t sb3;
int32_t sa4;
int32_t sb4;
int32_t sa5;
int32_t sb5;
int32_t sa6;
int32_t sb6;
int32_t freq = param_Walk + (inlet_Walk);
trace += freq >> 8;
outlet_Walk = trace >> 5;
int32_t base = ((trace >> 5) / 32 * (inlet_r1)) << 1;
int32_t mainspread = inlet_MainSprd;
int32_t spread1 = inlet_Sprd1;
int32_t spread2 = inlet_Sprd2;
int32_t expo = inlet_ExpSprd;
int32_t AM = inlet_AM;
int32_t ms1 = mainspread;
int32_t ms2 = mainspread * 2;
int32_t ms3 = mainspread * 3;
int32_t ms4 = mainspread * 4;
int32_t ms5 = mainspread * 5;
int32_t n2 = (base + ms1 - spread2);
int32_t n3 = (base + ms2 + spread2 + (expo ^ 2));
int32_t n4 = (base + ms3 + spread1 - spread2 + (expo ^ 3));
int32_t n5 = (base + ms4 + spread1 + (expo ^ 4));
int32_t n6 = (base + ms5 + spread1 + spread2 + (expo ^ 5));
int32_t ofs = inlet_s1;
c1 = ((base) - (((base) >> 21) << 21));
d1 = ((1 << 21) - c1);
sa1 = ((((base) >> 21) * inlet_s1));
sb1 = (((((base) >> 21) + 1) * inlet_s1));
if (sa1 >= 0)
k11 = ((unsigned int)sa1) / inlet_r1;
else
k11 = -(((unsigned int)(inlet_r1 - sa1)) / inlet_r1);
s11 = inlet_Min + sa1 - (k11 * inlet_r1);
if (sb1 >= 0)
k21 = ((unsigned int)sb1) / inlet_r1;
else
k21 = -(((unsigned int)(inlet_r1 - sb1)) / inlet_r1);
s21 = inlet_Min + sb1 - (k21 * inlet_r1);
c2 = ((n2) - (((n2) >> 21) << 21));
d2 = ((1 << 21) - c2);
sa2 = ((((n2) >> 21) * (inlet_s2 + ofs)));
sb2 = (((((n2) >> 21) + 1) * (inlet_s2 + ofs)));
if (sa2 >= 0)
k12 = ((unsigned int)sa2) / inlet_r1;
else
k12 = -(((unsigned int)(inlet_r1 - sa2)) / inlet_r1);
s12 = inlet_Min + sa2 - (k12 * inlet_r1);
if (sb2 >= 0)
k22 = ((unsigned int)sb2) / inlet_r1;
else
k22 = -(((unsigned int)(inlet_r1 - sb2)) / inlet_r1);
s22 = inlet_Min + sb2 - (k22 * inlet_r1);
c3 = ((n3) - (((n3) >> 21) << 21));
d3 = ((1 << 21) - c3);
sa3 = ((((n3) >> 21) * (inlet_s2 * 2 + ofs)));
sb3 = (((((n3) >> 21) + 1) * (inlet_s2 * 2 + ofs)));
if (sa3 >= 0)
k13 = ((unsigned int)sa3) / inlet_r1;
else
k13 = -(((unsigned int)(inlet_r1 - sa3)) / inlet_r1);
s13 = inlet_Min + sa3 - (k13 * inlet_r1);
if (sb3 >= 0)
k23 = ((unsigned int)sb3) / inlet_r1;
else
k23 = -(((unsigned int)(inlet_r1 - sb3)) / inlet_r1);
s23 = inlet_Min + sb3 - (k23 * inlet_r1);
c4 = ((n4) - (((n4) >> 21) << 21));
d4 = ((1 << 21) - c4);
sa4 = ((((n4) >> 21) * (inlet_s2 * 3 + ofs)));
sb4 = (((((n4) >> 21) + 1) * (inlet_s2 * 3 + ofs)));
if (sa4 >= 0)
k14 = ((unsigned int)sa4) / inlet_r1;
else
k14 = -(((unsigned int)(inlet_r1 - sa4)) / inlet_r1);
s14 = inlet_Min + sa4 - (k14 * inlet_r1);
if (sb4 >= 0)
k24 = ((unsigned int)sb4) / inlet_r1;
else
k24 = -(((unsigned int)(inlet_r1 - sb4)) / inlet_r1);
s24 = inlet_Min + sb4 - (k24 * inlet_r1);
c5 = ((n5) - (((n5) >> 21) << 21));
d5 = ((1 << 21) - c5);
sa5 = ((((n5) >> 21) * (inlet_s2 * 4 + ofs)));
sb5 = (((((n5) >> 21) + 1) * (inlet_s2 * 4 + ofs)));
if (sa5 >= 0)
k15 = ((unsigned int)sa5) / inlet_r1;
else
k15 = -(((unsigned int)(inlet_r1 - sa5)) / inlet_r1);
s15 = inlet_Min + sa5 - (k15 * inlet_r1);
if (sb5 >= 0)
k25 = ((unsigned int)sb5) / inlet_r1;
else
k25 = -(((unsigned int)(inlet_r1 - sb5)) / inlet_r1);
s25 = inlet_Min + sb5 - (k25 * inlet_r1);
c6 = ((n6) - (((n6) >> 21) << 21));
d6 = ((1 << 21) - c6);
sa6 = ((((n6) >> 21) * (inlet_s2 * 5 + ofs)));
sb6 = (((((n6) >> 21) + 1) * (inlet_s2 * 5 + ofs)));
if (sa6 >= 0)
k16 = ((unsigned int)sa6) / inlet_r1;
else
k16 = -(((unsigned int)(inlet_r1 - sa6)) / inlet_r1);
s16 = inlet_Min + sa6 - (k16 * inlet_r1);
if (sb6 >= 0)
k26 = ((unsigned int)sb6) / inlet_r1;
else
k26 = -(((unsigned int)(inlet_r1 - sb6)) / inlet_r1);
s26 = inlet_Min + sb6 - (k26 * inlet_r1);
// oscillators
MTOFEXTENDED(param_Pitch1 + inlet_Pitch, freq1);
MTOFEXTENDED(param_Pitch2 + inlet_Pitch, freq2);
MTOFEXTENDED(param_Pitch3 + inlet_Pitch, freq3);
MTOFEXTENDED(param_Pitch4 + inlet_Pitch, freq4);
MTOFEXTENDED(param_Pitch5 + inlet_Pitch, freq5);
MTOFEXTENDED(param_Pitch6 + inlet_Pitch, freq6);
// FM distribution
AlgoX = inlet_Algo;
if (AlgoX >= 0)
r = ((unsigned int)AlgoX) / (1 << 27);
else
r = -(((unsigned int)((1 << 27) - AlgoX)) / (1 << 27));
algoM = AlgoX - (r * (1 << 27));
AlgoX = inlet_Algo + inlet_ShiftStep + inlet_ShiftSecond + inlet_ShiftThirds;
if (AlgoX >= 0)
r = ((unsigned int)AlgoX) / (1 << 27);
else
r = -(((unsigned int)((1 << 27) - AlgoX)) / (1 << 27));
algo2 = AlgoX - (r * (1 << 27));
AlgoX = inlet_Algo + inlet_ShiftStep * 2 + inlet_ShiftThirds;
if (AlgoX >= 0)
r = ((unsigned int)AlgoX) / (1 << 27);
else
r = -(((unsigned int)((1 << 27) - AlgoX)) / (1 << 27));
algo3 = AlgoX - (r * (1 << 27));
AlgoX = inlet_Algo + inlet_ShiftHalf + inlet_ShiftStep * 3 + inlet_ShiftSecond;
if (AlgoX >= 0)
r = ((unsigned int)AlgoX) / (1 << 27);
else
r = -(((unsigned int)((1 << 27) - AlgoX)) / (1 << 27));
algo4 = AlgoX - (r * (1 << 27));
AlgoX = inlet_Algo + inlet_ShiftHalf + inlet_ShiftStep * 4 + inlet_ShiftThirds;
if (AlgoX >= 0)
r = ((unsigned int)AlgoX) / (1 << 27);
else
r = -(((unsigned int)((1 << 27) - AlgoX)) / (1 << 27));
algo5 = AlgoX - (r * (1 << 27));
AlgoX = inlet_Algo + inlet_ShiftHalf + inlet_ShiftStep * 5 + inlet_ShiftSecond +
inlet_ShiftThirds;
if (AlgoX >= 0)
r = ((unsigned int)AlgoX) / (1 << 27);
else
r = -(((unsigned int)((1 << 27) - AlgoX)) / (1 << 27));
algo6 = AlgoX - (r * (1 << 27));
// HP-filter FM
MTOF(param_HP, frq);// oscillators
// osc1
FM = ___SMMUL(SO1 << 3, freq1 << 6);
FM = ___SMMUL(FM << 3, inlet_FMW << 2);
Phase1a += freq1 + FM;
Phase1b = Phase1a >> 5;
// osc2
FM = ___SMMUL(SO2 << 3, freq2 << 6);
FM = ___SMMUL(FM << 3, inlet_FMW << 2);
Phase2a += freq2 + FM;
Phase2b = Phase2a >> 5;
// osc3
FM = ___SMMUL(SO3 << 3, freq3 << 6);
FM = ___SMMUL(FM << 3, inlet_FMW << 2);
Phase3a += freq3 + FM;
Phase3b = Phase3a >> 5;
// osc4
FM = ___SMMUL(SO4 << 3, freq4 << 6);
FM = ___SMMUL(FM << 3, inlet_FMW << 2);
Phase4a += freq4 + FM;
Phase4b = Phase4a >> 5;
// osc5
FM = ___SMMUL(SO5 << 3, freq5 << 6);
FM = ___SMMUL(FM << 3, inlet_FMW << 2);
Phase5a += freq5 + FM;
Phase5b = Phase5a >> 5;
// osc6
FM = ___SMMUL(SO6 << 3, freq6 << 6);
FM = ___SMMUL(FM << 3, inlet_FMW << 2);
Phase6a += freq6 + FM;
Phase6b = Phase6a >> 5;
// Harmonic morphing
a1 = Phase1b * s11;
b1 = Phase1b * s21;
SINE2TINTERP(a1 << 5, r11)
SINE2TINTERP(b1 << 5, r21)
x1 = ((___SMMUL((r11), (d1 << 7)) + ___SMMUL((r21), (c1 << 7))) >> 2);
a2 = Phase2b * s12;
b2 = Phase2b * s22;
SINE2TINTERP(a2 << 5, r12)
SINE2TINTERP(b2 << 5, r22)
x2 = ___SMMUL((___SMMUL((r12), (d2 << 7)) + ___SMMUL((r22), (c2 << 7))) << 1,
(14 << 25));
a3 = Phase3b * s13;
b3 = Phase3b * s23;
SINE2TINTERP(a3 << 5, r13)
SINE2TINTERP(b3 << 5, r23)
x3 = ___SMMUL((___SMMUL((r13), (d3 << 7)) + ___SMMUL((r23), (c3 << 7))) << 1,
(12 << 25));
a4 = Phase4b * s14;
b4 = Phase4b * s24;
SINE2TINTERP(a4 << 5, r14)
SINE2TINTERP(b4 << 5, r24)
x4 = ___SMMUL((___SMMUL((r14), (d4 << 7)) + ___SMMUL((r24), (c4 << 7))) << 1,
(10 << 25));
a5 = Phase5b * s15;
b5 = Phase5b * s25;
SINE2TINTERP(a5 << 5, r15)
SINE2TINTERP(b5 << 5, r25)
x5 = ___SMMUL((___SMMUL((r15), (d5 << 7)) + ___SMMUL((r25), (c5 << 7))) << 1,
(8 << 25));
a6 = Phase6b * s16;
b6 = Phase6b * s26;
SINE2TINTERP(a6 << 5, r16)
SINE2TINTERP(b6 << 5, r26)
x6 = ___SMMUL((___SMMUL((r16), (d6 << 7)) + ___SMMUL((r26), (c6 << 7))) << 1,
(6 << 25));
int32_t ring1 = ___SMMUL(x1 << 4, x2 << 5);
int32_t ring2 = ___SMMUL(x3 << 4, x4 << 5);
int32_t ring3 = ___SMMUL(x5 << 4, x6 << 5);
int32_t ring4 = ___SMMUL(ring1 << 3, ring2 << 4);
int32_t ring5 = ___SMMUL(ring4 << 3, ring3 << 4);
TO = (x1 + x2 + x3 + x4 + x5 + x6 + ___SMMUL(ring5 << 3, AM << 2)) >> 2;
val7 = ___SMMLA((TO - val7) << 1, frq, val7);
outlet_o1 = TO - val7;
// FM1
switch (int(algoM >> 24) > 0 ? algoM >> 24 : 0) {
case 0:
aG = 0;
break;
case 1:
aG = x1;
break;
case 2:
aG = x2;
break;
case 3:
aG = x3;
break;
case 4:
aG = x4;
break;
case 5:
aG = x5;
break;
case 6:
aG = x6;
break;
case 7:
aG = AM;
break;
default:
aG = 0;
break;
}
switch (int(algoM >> 24) > 0 ? algoM >> 24 : 0) {
case 0:
bG = x1;
break;
case 1:
bG = x2;
break;
case 2:
bG = x3;
break;
case 3:
bG = x4;
break;
case 4:
bG = x5;
break;
case 5:
bG = x6;
break;
case 6:
bG = AM;
break;
case 7:
bG = 0;
break;
default:
bG = x1;
break;
}
cG = algoM - ((algoM >> 24) << 24);
dG = (1 << 24) - cG;
SO1 = ___SMMUL(dG << 4, aG << 4) + ___SMMUL(cG << 4, bG << 4);
val1 = ___SMMLA((SO1 - val1) << 1, frq, val1);
SO1 = SO1 - val1;
// FM2
switch (int(algo2 >> 24) > 0 ? algo2 >> 24 : 0) {
case 0:
aG = 0;
break;
case 1:
aG = x1;
break;
case 2:
aG = x2;
break;
case 3:
aG = x3;
break;
case 4:
aG = x4;
break;
case 5:
aG = x5;
break;
case 6:
aG = x6;
break;
case 7:
aG = AM;
break;
default:
aG = 0;
break;
}
switch (int(algo2 >> 24) > 0 ? algo2 >> 24 : 0) {
case 0:
bG = x1;
break;
case 1:
bG = x2;
break;
case 2:
bG = x3;
break;
case 3:
bG = x4;
break;
case 4:
bG = x5;
break;
case 5:
bG = x6;
break;
case 6:
bG = AM;
break;
case 7:
bG = 0;
break;
default:
bG = x1;
break;
}
cG = algo2 - ((algo2 >> 24) << 24);
dG = (1 << 24) - cG;
SO2 = ___SMMUL(dG << 4, aG << 4) + ___SMMUL(cG << 4, bG << 4);
val2 = ___SMMLA((SO2 - val2) << 1, frq, val2);
SO2 = SO2 - val2;
// FM3
switch (int(algo3 >> 24) > 0 ? algo3 >> 24 : 0) {
case 0:
aG = 0;
break;
case 1:
aG = x1;
break;
case 2:
aG = x2;
break;
case 3:
aG = x3;
break;
case 4:
aG = x4;
break;
case 5:
aG = x5;
break;
case 6:
aG = x6;
break;
case 7:
aG = AM;
break;
default:
aG = 0;
break;
}
switch (int(algo3 >> 24) > 0 ? algo3 >> 24 : 0) {
case 0:
bG = x1;
break;
case 1:
bG = x2;
break;
case 2:
bG = x3;
break;
case 3:
bG = x4;
break;
case 4:
bG = x5;
break;
case 5:
bG = x6;
break;
case 6:
bG = AM;
break;
case 7:
bG = 0;
break;
default:
bG = x1;
break;
}
cG = algo3 - ((algo3 >> 24) << 24);
dG = (1 << 24) - cG;
SO3 = ___SMMUL(dG << 4, aG << 4) + ___SMMUL(cG << 4, bG << 4);
val3 = ___SMMLA((SO3 - val3) << 1, frq, val3);
SO3 = SO3 - val3;
// FM4
switch (int(algo4 >> 24) > 0 ? algo4 >> 24 : 0) {
case 0:
aG = 0;
break;
case 1:
aG = x1;
break;
case 2:
aG = x2;
break;
case 3:
aG = x3;
break;
case 4:
aG = x4;
break;
case 5:
aG = x5;
break;
case 6:
aG = x6;
break;
case 7:
aG = AM;
break;
default:
aG = 0;
break;
}
switch (int(algo4 >> 24) > 0 ? algo4 >> 24 : 0) {
case 0:
bG = x1;
break;
case 1:
bG = x2;
break;
case 2:
bG = x3;
break;
case 3:
bG = x4;
break;
case 4:
bG = x5;
break;
case 5:
bG = x6;
break;
case 6:
bG = AM;
break;
case 7:
bG = 0;
break;
default:
bG = x1;
break;
}
cG = algo4 - ((algo4 >> 24) << 24);
dG = (1 << 24) - cG;
SO4 = ___SMMUL(dG << 4, aG << 4) + ___SMMUL(cG << 4, bG << 4);
val4 = ___SMMLA((SO4 - val4) << 1, frq, val4);
SO4 = SO4 - val4;
// FM5
switch (int(algo5 >> 24) > 0 ? algo5 >> 24 : 0) {
case 0:
aG = 0;
break;
case 1:
aG = x1;
break;
case 2:
aG = x2;
break;
case 3:
aG = x3;
break;
case 4:
aG = x4;
break;
case 5:
aG = x5;
break;
case 6:
aG = x6;
break;
case 7:
aG = AM;
break;
default:
aG = 0;
break;
}
switch (int(algo5 >> 24) > 0 ? algo5 >> 24 : 0) {
case 0:
bG = x1;
break;
case 1:
bG = x2;
break;
case 2:
bG = x3;
break;
case 3:
bG = x4;
break;
case 4:
bG = x5;
break;
case 5:
bG = x6;
break;
case 6:
bG = AM;
break;
case 7:
bG = 0;
break;
default:
bG = x1;
break;
}
cG = algo5 - ((algo5 >> 24) << 24);
dG = (1 << 24) - cG;
SO5 = ___SMMUL(dG << 4, aG << 4) + ___SMMUL(cG << 4, bG << 4);
val5 = ___SMMLA((SO5 - val5) << 1, frq, val5);
SO5 = SO5 - val5;
// FM6
switch (int(algo6 >> 24) > 0 ? algo6 >> 24 : 0) {
case 0:
aG = 0;
break;
case 1:
aG = x1;
break;
case 2:
aG = x2;
break;
case 3:
aG = x3;
break;
case 4:
aG = x4;
break;
case 5:
aG = x5;
break;
case 6:
aG = x6;
break;
case 7:
aG = AM;
break;
default:
aG = 0;
break;
}
switch (int(algo6 >> 24) > 0 ? algo6 >> 24 : 0) {
case 0:
bG = x1;
break;
case 1:
bG = x2;
break;
case 2:
bG = x3;
break;
case 3:
bG = x4;
break;
case 4:
bG = x5;
break;
case 5:
bG = x6;
break;
case 6:
bG = AM;
break;
case 7:
bG = 0;
break;
default:
bG = x1;
break;
}
cG = algo6 - ((algo6 >> 24) << 24);
dG = (1 << 24) - cG;
SO6 = ___SMMUL(dG << 4, aG << 4) + ___SMMUL(cG << 4, bG << 4);
val6 = ___SMMLA((SO6 - val6) << 1, frq, val6);
SO6 = SO6 - val6;